Estimated reading time: 12 minutes
while $sun; do make hay; done¶
Warning
This is a massive brain dump, which I plan to rewrite in to a series at some point. However, until that imaginary date arrives…
I have a fondness for make, but don’t quite know why. On some days it is the bane of my life, and I feel we could do better. It is, however, incredibly useful and allows us to easily perform so many of the repetitive tasks we in the software world have lucked ourselves in to.
One project that I’ve worked on for a decade has ten thousand lines of hand
written Makefiles, which is just plain ridiculous. Nobody should be
hand writing that much build infrastructure, even if it started with good
intentions and a scant 120 lines.
Which make?¶
A hardly insignificant number of those 10,000 lines are to workaround incompatibilities in various tools that advertise themselves as make. Forcing a dependency on GNU make wouldn’t suddenly drop the line count by 60% or magically transform the robustness of our builds, but it would help.
I’ll take a tiny example from the project I’m working on right now. Which common versions of make will it fail on and why?
MAKE_SUBDIRS ::= …
m/clean: $(subst m/clean,,$(MAKE_SUBDIRS:%=%/clean))
+echo "Don’t use 'make -n' to test without side effects either"
We even have a 800 line Makefile.debug include which defines
a namespace of subcommands(like the maintainer namespace above) to aid
when the inevitable errors show up. Most of the stuff in that file is
absolutely amazing, I’m working with a few genuine make masters.
I am not a make master.
I often find myself forgetting which make supports some feature, or which one fails horribly when you use that one “standard” feature every make supports. Even in the minutia of the build there are things that are subobtimal, for example in the previously mentioned project there are a variety of suffix rules and pattern rules which could be uniform if only we’d managed to force a specific style1.
Late last year I posted the following note:
Just finished my 1º #guile make extension… TIL none of our CI servers have #make with #guile support, and many devs have pre-GPL3 make.
It is still mostly true, our build servers and many developers still don’t have
a guile enabled GNU make. The build servers don’t because guile
support isn’t enabled in the packages for some reason, and the devs that use
systems which refuse to ship a recent enough versions of GNU make to avoid
the GPL32 don’t have it either.
There has to be a better way…
redo¶
djb’s redo is a huge step in the right direction3, but its various implementations are plagued by many of the problems that make has. There is no single tool that can uniformly be recognised as redo, in fact it feels like somehow there are as many implementations of redo floating around as there are of make even though it is thirty years younger.
While redo is awesome in many of its implementations you find yourself having
to remember the idiosyncrasies of yet another collection of slightly
incompatible tools. If you’re using Avery Pennarun’s popular Python
implementation then you may not remember to make your .do files
executable or to give them a proper #! line, as it doesn’t necessarily
require them. If you using Jonathan de Boyne Pollard’s impressive C
implementation you may not remember that you don’t have redo-stamp
available to you. As redo is less common specifying the exact tool you’re
calling redo is far easier than with make though, and I’m yet to see an
angry issue reported in projects that do so4.
So, once you’ve managed to keep your eyes on the shifting landscape — or have
forced a specific implementation of redo — you have to turn your attention to
your .do files. Is /bin/sh bash, dash, or something else
entirely? Is that large find to xargs pipe you’re using
to pump redo-ifchange going to fail because some platform’s
find treats links differently? Do you need to specify
gsed on MacOS to work around issues with the default sed
command? As a first port of call at least run checkbashisms from
the devscripts package on your public .do files.
I mean — to an extent — you need to be on top of these things in your make
usage too, but you’re likely to have far more complex .do files than the
shell incantations in your rule’s recipes.
Tip
If you’re using the Python redo implementation you should be considering
the speed of the tools too, so as to not adversely affect your build times.
For example, it is good practice to collect all dependencies before
calling redo-ifchange instead of staggering their addition
throughout your .do file as you encounter them.
All this is worth the cost though. You end up with stable, self encapsulated build rules such as the following:
redo-ifchange ./.meta/cc ./.meta/cflags
read cc < ./.meta/cc
read ccflags < ./.meta/cflags
$cc $cflags -o "$3" -c "$2.c" -MD -MF "$2.d"
sed -e "s|^$3:||" "$2.d" | xargs redo-ifchange
That is a cropped excerpt from a project’s default.o.do. It defines
a rule that builds .o files from their corresponding .c file, and it
makes sure those files are rebuilt in the event that you change the value of
CC or CFLAGS. It also handles all the dependencies your
#include directives gave by taking advantage of the compiler’s knowledge of
the build. Implementing the same functionality with make is far more
convoluted, and requires a heap of code if you wish to use finer grained
controls than simply rebuilding everything by depending on your
Makefile from within your rules.
Still redo is a big leap forward from plain make, and I do recommend it. I even gave a talk on it at LoFu ‘16, and I know some people switched after hearing that as I’ve been fielding informal support requests ever since ;)
gup¶
I want to give Tim Cuthbertson’s gup an honourable mention here. gup is an improved redo implementation, but is wholly incompatible with it. It is available in both a Python and ocaml version. It fixes a few of the most annoying problems in redo, but operates in largely the same way conceptually. Any of the skills you’ve learnt with redo are easy to transfer, and you can update your builds to use gup with very little effort.
I’m a big fan of gup, and for a couple of years I even used it to power my home directory having moved on from make. An excerpt from my homedir’s debug support can perhaps serve as an example of its usage:
#!sh
self=$(realpath $0)
if [ $self = ${HOME}/gup/lib.sh ]; then
echo "$0: Only for use within a gup file" >&2
exit 255
fi
[ "${GUP_XTRACE:-0}" -eq 1 ] && set -x
[ "$GUP_VERBOSE" -ge 1 ] && set -v
set -eu
gup -u $self
Outside of my own projects I’ve never seen gup in use, which anecdotally makes it even less common than redo. Whether that is a deal breaker for you isn’t for me to decide, but I would recommend that you check it out if you’re considering using redo.
I want to add a final note that Tim is nice to work with. I’ve filed bugs in other projects that he maintains and it has been a good experience each time. I’m sure you’ll get the same great service if you were to find a problem in gup!
ninja¶
Enter the ninja. I’ve switched many projects to ninja, but not because it is my new favourite tool. I’ve switched entirely because it feels like it has the momentum to supplant make. Given the choice I’d honestly rather see a redo implementation such as gup succeed, but ninja is a great alternative.
I’ll make a confession here, my home directory now requires ninja. Yes, my config files have made the progression from make to redo to gup and now to ninja.
$ alias homeninja
homeninja='ninja -C ~ -j1'
$ homeninja -t targets | wc -l
423
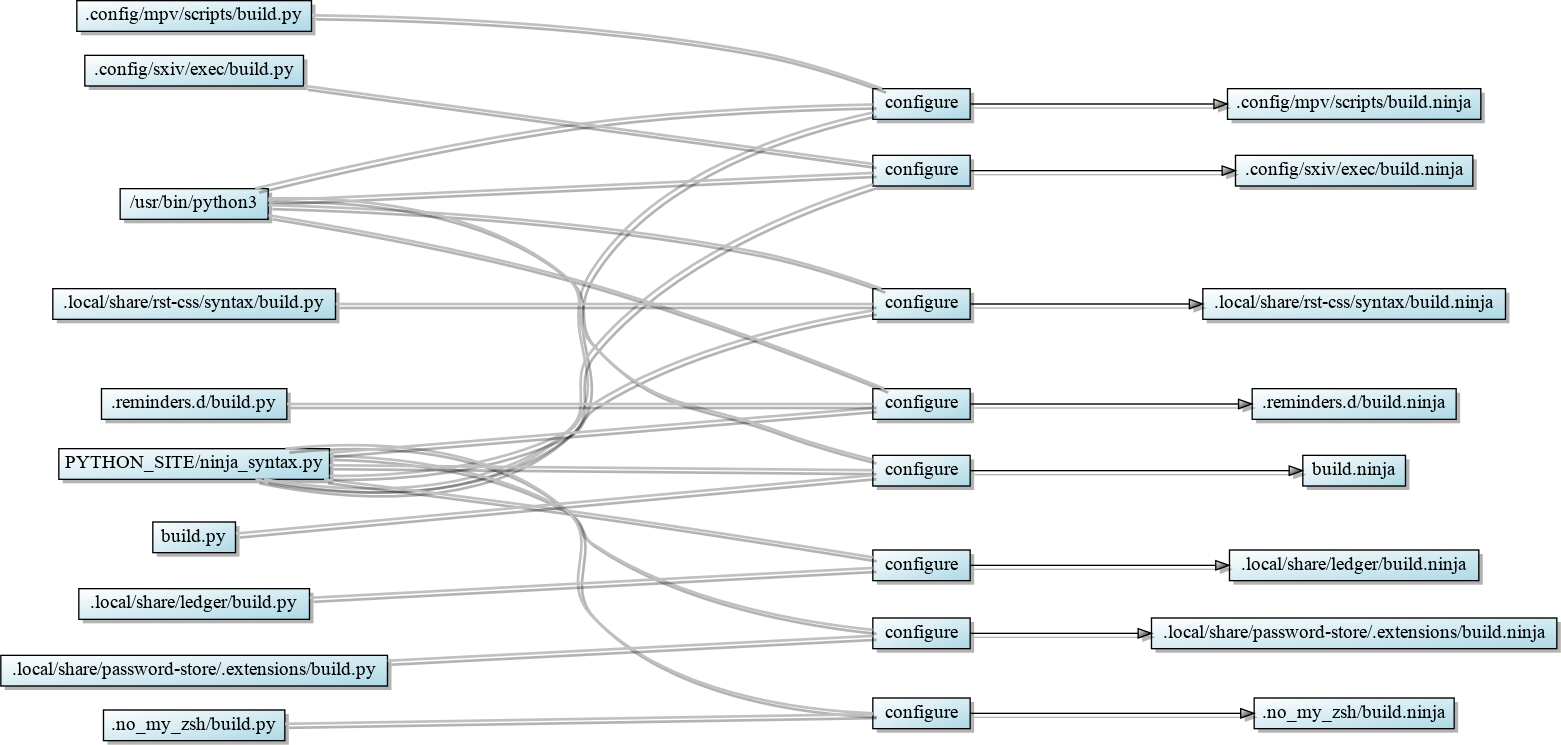
A chunk of the DAG for my home directory under ninja. The full image is both chock full of private data and 9 MB(29000 pixels tall), so I’ll save all of us from that.¶
We’ve already seen a benefit of ninja here, it can immediately display
a DAG to help in debugging by giving the option -t graph. While both
gup and redo can be easily tamed to produce a simple graphviz image as
above5, doing so with make is very difficult6.
ninja shares a lot in common with redo. It automatically depends on its build rules, and any changes to them cleanly ripple out through the build. It also makes adding computed dependencies very easy, although you need to mangle them in to make format instead of extracting from make format as you would have with redo. A quick example of how to make docutils dependencies work is below:
command = rst2html.py --record-dependencies $out.d.tmp $in $out; $
[ -f $out.d.tmp ] && echo $out: $$(cat $out.d.tmp) > $out.d; $
rm -f $out.d.tmp
depfile = $out.d
deps = gcc
Of course we’re making a trade-off at this point, and they are basically:
Tool |
Simple tasks |
Complex tasks |
|---|---|---|
make |
Easy |
Tricky, and brittle |
redo |
Easy |
Repetitive, but simple |
ninja |
Easy |
Offload to another tool |
ninja really does make the easy parts easy, and there are a variety of tools to work with more complex builds. You might even find you can get away with a tiny bit of scripting around ninja_syntax, but the manual work will quickly build up with that approach.
meson¶
The meson build system is probably the frontrunner today.
In a move that feels like it is simply meant to annoy the people behind
suckless I use meson to build my dwm configuration. Not because it is in
an important choice, but solely because it was a small and simple package that
made learning the basics of meson easier. A trimmed down version of the
meson.build is below:
project('dwm', ['c', ], default_options: ['std=c99', ], license: 'MIT')
fontconfig_dep = dependency('fontconfig')
x11_dep = dependency('x11')
xft_dep = dependency('xft')
xinerama_dep = dependency('xinerama', required: false)
if xinerama_dep.found()
add_project_arguments('-DXINERAMA', language: 'c')
endif
config_h = custom_target('gen-config', input: 'config.def.h',
output: 'config.h',
command: ['cp', '--no-clobber', '@INPUT@',
'@OUTPUT@'])
executable('dwm', ['drw.c', 'dwm.c', 'util.c', config_h],
dependencies: [fontconfig_dep, x11_dep, xft_dep, xinerama_dep],
install: true)
install_man('dwm.1')
This is broadly comparable with an autoconf and automake solution for
a similar task, albeit with far less behind the scenes complexity. It is
a superior solution to upstream’s choice of hand editing a Makefile, as
it handles rebuilds when you change options automatically too.
meson supports many languages out of the box; C, C++, vala, rust, &c. If you find yourself needing to add your own it is quite simple, just subclass Compiler and set a few methods. It took less than five minutes to add support for the transpiler we use on some of our projects7, and probably another 10 a few weeks later to tighten it up and add tests when meson support was merged.
In fact because meson is such a well defined wrapper around ninja I’d
recommend it after ninja. If you start a small project where a simple
static build.ninja is enough, then “upgrading” to meson iff the
need arises at some point is really easy.
Hint
Co-workers can see this in action in the zephyr_ground_station
repository. I started out with mock up graphics from the Zephyr spec,
added a manual build.ninja as I started to code the interface,
switched to a simple generated file using ninja’s ninja_syntax
module when the project grew, and eventually changed to meson with a few
edits when the project was eventually greenlit. It was a really clean
process, and one I’d follow again.
Google’s kati¶
kati is a nice first step if you’re currently using make and want to try out
ninja. It will generate a build.ninja from your Makefile,
but it won’t be very idiomatic.
It does serve as an immediate example of the difference you get with a no-op
build from make and ninja though, and sometimes that alone feels like
enough to integrate kati in to your build.
Because it mechanically converts rules from make to ninja it is incredibly verbose, but it does so in such a manner that it is easy to use the output as a basis for full switch.
Attention
I should mention cmake at least once, just so that readers know that
I’m aware of it. I’m ignoring it because of its inscrutable syntax, its
interesting pkg-config story, its propensity for creating ten minute
multi-pass pre-build steps, and its love for running the cmake
binary thousands of times in each build.
Conclusions¶
There are a lot of options available if you’re feeling growing pains with make, or are just looking to tighten up builds. I’ve covered a few here, but there are many more out there. I’ve ignored a few excellent options that fit within the realms of what we commonly refer to as a build system(premake and tup both spring to mind), in part because I don’t have enough real world experience to comment on them.
This has turned in to a much longer document than I had originally envisioned, but I hope there is enough meat in to make that worthwhile.
Finally, in much the same way I tend to finish my build system talks with an offer to help in the final slide, I’ll add one here too. If you’ve made it this far and need a little help, don’t hesitate to get in contact.
Footnotes
- 1
From today that should be no more. I’ve added a rule to break the build if you add a suffix rule, but I’m sure we’ll see some commentary on whether that was the right way to pin it.
- 2
For the projects I’m currently working the number of devs using systems with pre-GPL3 make is very low, but it is entirely dependent on the ecosystem of a given project.
- 3
It is defined only in a collection of short descriptions on djb’s website, and there is no known reference implementation.
- 4
This is definitely not true of make requirements, I’ve seen many ridiculously angry bugs filed when builds only work with GNU make.
- 5
Avery Pennarun’s Python implementation of redo stores it dependency data in a sqlite database named
.redo/redo.sqlite3, making it is easy to transform in to a dot compliant input. For instance, here is mydzen2tree as built by redo: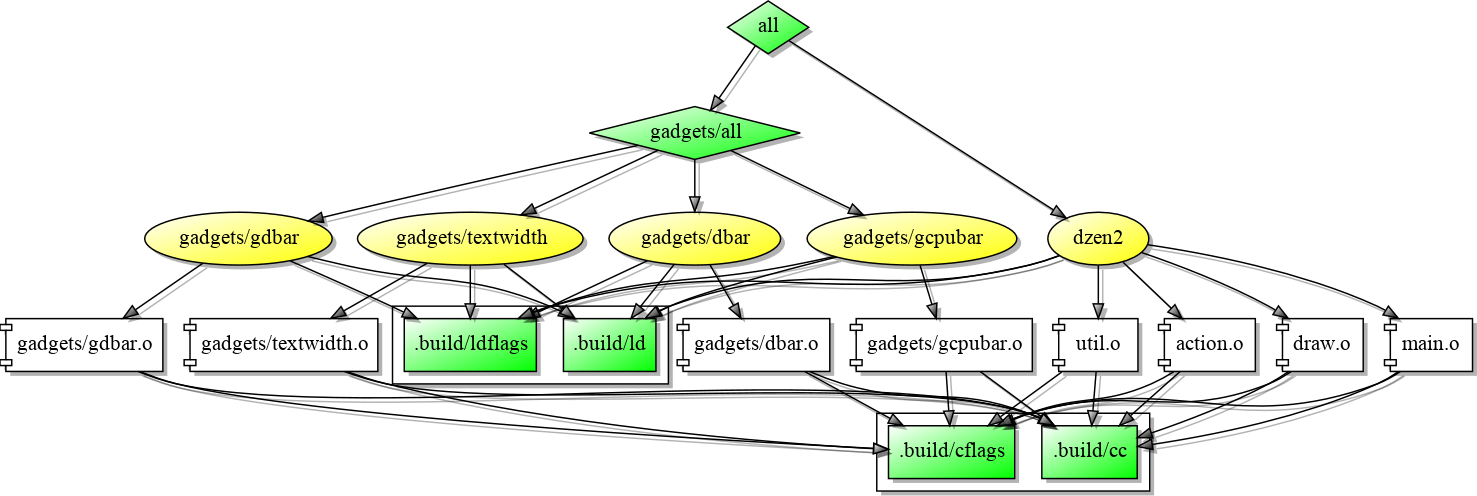
- 6
A search yields a few attempts to do so, many requiring large runtimes and all with a list of limitations likely to fall far below a projects actual usage of make. The two I popped open rely on parsing the output from make -pn for example, and neither took in to account
+code execution either.- 7
If you need a custom compiler the vala support is probably a good starting point as it is not too complex, and implements a good subset of required interface.
Authenticate this page by pasting this signature into Keybase.
Have a suggestion or see a typo? Edit this page