Estimated reading time: 25 minutes
Advent of Code 2020¶
I’m done.
I’ve given up on AoC for this year. I’m writing this as a journal entry, more for myself than others. You’ve been warned!
Note
As always Advent of Code is fun, even when it doesn’t always feel like it. If you’re enjoying it, or currently screaming at it, tip the creator so that we can smile and shout at it next year.
Why quit?¶
I’m in the habit of quitting early now. Each year I spank through the puzzles until I lose interest, give up, and then complete the puzzles through the Winterval break.
The tipping point for me this year was day 16, the text was just impenetrable to me. It literally took me four times as long to parse the description as it did to code the solution.
I have 32 stars for completing both parts of every day so far this year, but I’m taking a break until I have a bit more downtime.
Day 1¶
I jumped in with my toolset from previous years, so my solution for part one is:
from itertools import combinations
from typing import List
from utils import aoc_run, read_data
@aoc_run({
'1721\n979\n366\n299\n675\n1456': 514579,
},
800139
)
@read_data
def part1(inputs: List[str]) -> int:
return [x * y for x, y in combinations(map(int, inputs), 2)
if x + y == 2020][0]
The aoc_run decorator still configures a test runner using the examples
from the description, and if provided the second argument confirms my output
when I’m refactoring the code. If the second argument isn’t provided, such as
when you’re writing your code, it will output the result for you to submit.
I didn’t — and still don’t — like the actual meat, but that is the sort of thing that ends up in a REPL session when you’re watching the clock.
Given that part 2 was simply extending the criteria to matching three numbers,
we just need to change the r parameter to the
combinations() call.
In hindsight I’d rather see something like:
return next(
reduce(mul, comb)
for xs in combinations(map(int, numbers), length)
if sum(xs) == total
)
However, it is unclear to me whether that is actually clearer in the general case, or simply the eye I have given my current daytime project.
Day 2¶
A little input parsing required today, because I don’t need two problems
I reached for translate() and split():
_UNFORMAT = str.maketrans({':': ' ', '-': ' '})
def extract_data(s: str) -> Tuple[List[int], str, str]:
*ps, char, password = s.translate(_UNFORMAT).split()
ps = [int(p) for p in ps]
return ps, char, password
Here we configure a simple translator that replaces the field separators in the
input with a space, allowing split() to break each line for us.
Plenty of other solutions are clearly available, such as a regular expressions:
matcher = re.compile(r'(?P<min>\d+)-(?P<max>\d+) (?P<char>.): (?P<password>.*)')
or even parse:
min, max, char, password = parse.parse('{:.2d}-{:.2d} {:.1l}: {}', line)
It doesn’t make much difference for the inputs in this case, but it should be
noted that parse is considerably slower than the regular expression and
the more manual extract_data function.
Which leaves us with a simple loop for part one:
def part1(inputs: List[str]) -> int:
valid = 0
for l in inputs:
(low, high), char, password = extract_data(l)
count = Counter(password)[char]
if low <= count <= high:
valid += 1
return valid
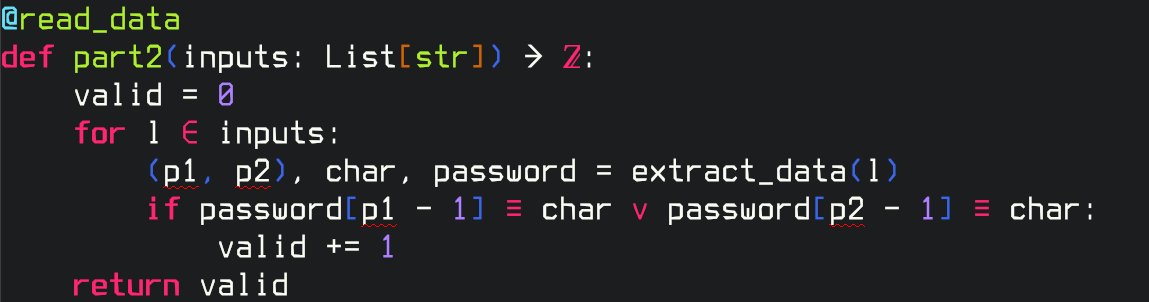
Part two is largely the same, with a slight tweak:
def part2(inputs: List[str]) -> int:
valid = 0
for l in inputs:
(p1, p2), char, password = extract_data(l)
if (password[p1 - 1] == char) ^ (password[p2 - 1] == char):
valid += 1
return valid
My admission here is that my first attempt failed to spot that we wanted an XOR here, and I failed in spite of the fact my editor shows disjunction symbolically. And yes, the “exactly one of these positions” text really is in bold on that page.
Day 3¶
We’re walking a wrapping map from our input this time. There are heaps of ways to model this, I went with the quickest I could think of:
from itertools import count
def traverse_map(inputs: List[str], step_x: int, step_y: int) -> int:
height, width = len(inputs), len(inputs[0])
return sum(
1
for pos_x, pos_y in zip(
count(step_x, step_x), range(step_y, height, step_y)
)
if inputs[pos_y][pos_x % width] == '#'
)
def part1(inputs: List[str]) -> int:
return traverse_map(inputs, 3, 1)
Depending on how you feel about generator expressions you may prefer a more literal loop:
def traverse_map(inputs: List[str], step_x: int, step_y: int) -> int:
height, width = len(inputs), len(inputs[0])
trees_hit = 0
pos_x, pos_y = step_x, step_y
while pos_y < height:
if inputs[pos_y][pos_x % width] == '#':
trees_hit += 1
pos_x += step_x
pos_y += step_y
return trees_hit
I find the sum() far more readable, but it is definitely a matter of
taste. I know that taste doesn’t translate well to my co-workers, and
I wouldn’t commit a function like that in to a shared repository(no matter how
much I prefer it).
The inability to use tuple unpacking alongside += makes this annoying in my
eyes too. pos_x, pos_y += step_x, step_y would be far nicer. A simple
alternative is either to create a point class or abuse complex numbers to hold
the x and y coordinates.
Part two requires simply performing the same procedure with a few different
step values. I had seen that coming, and was already prepared in my
traverse_map() function:
def part2(inputs: List[str]) -> int:
return reduce(
mul,
[
traverse_map(inputs, step_x, step_y)
for step_x, step_y in [(1, 1), (3, 1), (5, 1), (7, 1), (1, 2)]
],
)
Day 4¶
I’m lazy, really lazy. Instead of doing The Right Thing™ and making
read_data support returning paragraphs, I simply rejoined the inputs I had
already split for this puzzle:
def part1(inputs: List[str]) -> int:
passports = []
for passport in '\n'.join(inputs).split('\n\n'):
passports.append(dict(chunk.split(':') for chunk in passport.split()))
and with the passport data parsed, it was simply a matter of iterating over
them while ignoring the cid field:
fields = {'byr', 'iyr', 'eyr', 'hgt', 'hcl', 'ecl', 'pid', 'cid'}
return sum(
1
for passport in passports
if set(passport.keys()) | {'cid', } == fields
)
Every year I tell myself I should use a different language for AoC, but so
often Python simply provides exactly the tools you’ll want. Today it is the
set, other days it is the itertools module
Part two is just a huge collection of if statements wrapped in a for-loop,
mostly implemented with paste and a vim macro.
I did toy with the idea of a quick class to handle the passports, but even with attrs all the validators would have significantly ballooned the implementation. Even the birth year would have been a heap of lines:
@attr.s
class Passport:
byr: int = attr.ib(metadata={'name': 'Birth Year'})
@byr.validator
def byr_check(self, attribute, value):
if not 1920 <= int(value) <= 2002:
raise ValueError(f'Invalid birth year {value!r}')
Day 5¶
This is one of those “do it right or do it quick” puzzles, I leaned toward “do
it quick”. Taking advantage of translate() again, we can just
pretend the characters are binary representations of the value:
CODE_TABLE = str.maketrans({'F': '1', 'B': '0', 'L': '1', 'R': '0'})
def decode_pass(code: str) -> int:
row = int(code[:7].translate(CODE_TABLE), 2) ^ 127
col = int(code[7:].translate(CODE_TABLE), 2) ^ 7
return (row * 8) + col
With that part one is simple as:
max(map(decode_pass, inputs))
Similarly, part two is just a dirty loop over the seats in the REPL:
seats = list(map(decode_pass, inputs))
for seat in range(min(seats), max(seats)):
if seat in seats:
continue
if seat - 1 in seats and seat + 1 in seats:
break
print(seat)
Day 6¶
My earlier laziness comes back to haunt me here. I should have just made
reading paragraphs a thing on day four. I took the hint and changed my
read_data decorator to support a separator. With that we’re a one-liner
away from an answer:
from functools import reduce
from operator import or_
@read_data('\n\n')
def part1(inputs: List[str]) -> int:
return sum(len(reduce(or_, map(set, group.splitlines())))
for group in inputs)
This definitely feels like cheating, as basically all we’re doing here is
calling set to uniquify the inputs. Again, I wouldn’t commit this to
a shared repository, but it is how I REPL in private.
Part two is almost identical, we’re just replacing the operand for
reduce():
from operator import and_
@read_data('\n\n')
def part2(inputs: List[str]) -> int:
return sum(len(reduce(and_, map(set, group.splitlines())))
for group in inputs)
If you’ve made it this far, I wonder if you can guess what language my current daytime project is written in. There is a small prize in it for the first person to correctly guess based on the solutions to these puzzles.
Day 7¶
Hmm, we’re back in networkx territory again. Every year a puzzle pops up where just knowing what networkx is gives you the answer, today is the first such one this year.
I parsed the input text using a dirty little loop:
from re import findall
def parse_rules(inputs: List[str]) -> Dict[str, List[Dict[str, int]]]:
rules = {}
for line in inputs:
name = ' '.join(line.split()[:2])
rules[name] = {k: int(v) for v, k in findall(r'(\d+) (\w+ \w+)', line)}
return rules
We’re creating a dictionary where the key is first two words of a line, and the
value is a dictionary which is basically a self-reference and a count. The
findall() call is just pulling out all matches of a number followed
by two words.
Dumping that data in to a networkx DiGraph object allows us simply
count the ancestors using the, ehm… networkx.ancestors() function.
We didn’t really need the full data in our graph here, but all AoC players know we’re going to need the bag counts for part two.
Even if you’d prefer not to use graphviz or networkx, you could write a simple recursive solution for part two such as:
def walk_bags(rules, bag):
return 1 + sum(walk_bags(rules, bag_name) * bag_count
for bag_name, bag_count in rules[bag].items())
Note
I suspect I would have made the ballooning off-by-one error if I had chosen this route on the day.
I had assumed the input would have been crazy enough to break Python’s default recursion limit, but it looks like we were nowhere near it. Things aren’t getting evil… yet.
Day 8¶
Memories of the IntCode interpreter from last year immediately entered my mind here. Should we be making a generic virtual machine straight away to speed up the following days?
There is actually very little of interest in today’s solution, the only oddity
at all was that I added a branch for the nop for some reason. It is
a no-operation, how could it possibly need a handler?
The issue I did have trouble with was the runtime being far too long. My initial effort in the REPL took 17 seconds, and that felt very wrong. On closer inspection I was stupidly re-parsing the input on each loop for part two, but even that shouldn’t have been that slow. Let’s ask hyperfine
$ hyperfine 'python3 day08.py'
Benchmark #1: python3 day08.py
Time (mean ± σ): 17.825 s ± 1.145 s [User: 15.329 s, System: 0.017 s]
Range (min … max): 16.104 s … 19.153 s 10 runs
Kicking the parsing out of the loop is a huge improvement:
$ hyperfine 'python3 day08.py'
Benchmark #1: python3 day08.py
Time (mean ± σ): 238.9 ms ± 5.1 ms [User: 214.2 ms, System: 13.8 ms]
Range (min … max): 234.9 ms … 253.7 ms 11 runs
Turns out using parse to grab the data is quite expensive. Switching to regular string splitting like so:
def parse():
insts = []
for line in inputs:
op, val_s = line.split()
insts.append((op, int(val_s)))
return insts
is much faster:
$ hyperfine 'python3 day08.py'
Benchmark #1: python3 day08.py
Time (mean ± σ): 143.7 ms ± 24.4 ms [User: 115.4 ms, System: 14.5 ms]
Range (min … max): 132.9 ms … 239.6 ms 19 runs
I suspect I wouldn’t have noticed the impact of parse, if I hadn’t messed up the parsing in a rush to score on the local leaderboard. However, once you start poking around there is a multitude of rabbit holes to climb in to if you want to extract some speed.
Day 9¶
My laziness pushed me to produce a really awful solution for part one:
from itertools import combinations
def find_invalid(data: List[int], buf_len: int) -> int:
val = 0
for pos, val in enumerate(data[buf_len:], buf_len):
possibles = set(map(sum, combinations(data[pos - buf_len:pos], 2)))
if val not in possibles:
break
return val
For each number it generates a complete set of possible values, which could be summing as many as 300 values on each loop. I’m not proud of it, but this is what time limited puzzles make you do.
I did at least use a sliding sum for part two, although to be frank even using a filthy and dumb solution wouldn’t have been an issue as the problem space is small enough. To prove that to myself I’ve just written a version without a sliding sum:
invalid = find_invalid(data, buf_len)
for x in range(len(data)):
for y in range(len(data) - x):
if sum(data[x:y]) == invalid:
block = data[x:y]
print(min(block) + max(block))
The above needs a hyperfine benchmark just to spot the difference in runtime to the sliding sum version. And you can even bring it to within spitting distance with an early exit:
from itertools import accumulate, takewhile
invalid = find_invalid(data, 25)
for start in range(len(data)):
try:
end = next(
end
for end, val in takewhile(
lambda x: x[1] <= invalid,
enumerate(accumulate(data[start:]), start),
)
if val == invalid
)
except StopIteration:
continue
else:
block = data[start:end]
break
print(min(block) + max(block))
But… Don’t. Do. It.
Day 10¶
Part one was a lot of text to say sort the list:
@read_data
def part1(inputs: List[str]) -> int:
adapters = sorted(int(line) for line in inputs)
res = [
x - y
for x, y in zip(
adapters + [adapters[-1] + 3],
[0, ] + adapters,
)
]
return res.count(1) * res.count(3)
Part two felt the same, a lot of text but a line or two in the REPL:
chain = [1, ] + [0, ] * adapters[-1]
for adapter in adapters:
chain[adapter] = sum(chain[max(adapter - 3, 0):adapter])
print(chain[adapter])
As you can probably tell I wasn’t particularly happy with this day. I’ve wondered if I was just lucky with my input, but it doesn’t appear so.
Day 11¶
Argghh, I misread part one and accidentally solved part two.
Much like other years there is time when numpy
quickly comes in to its own. Today is one of those. Being able to address our
floor plan with array[x1:x2,y1:y2] via numpy saves us needing to
dig around manually when looking for neighbouring cells.
I think the only marginally interesting snippet here was handling of the toggling:
if cell:
if sum(neighbours) >= 4:
new_plan[row_no][col_no] = False
else:
if not any(neighbours):
new_plan[row_no][col_no] = True
The sum(neighbours) call is taking advantage of Python treating True as
1, such that sum([True, True, False]) equals 2.
For part two, numpy provides a diagonal method which we can then
filter for a given value. In my case it just looks for the first
non-None, and then it is simply a matter of changing the four to a five
in our seat toggling branch.
numpy is cheating, but not using it is needless busywork.
Day 12¶
Move along, nothing to see here. Huge, ugly multi-armed if-statement. Hat tip to my co-worker Tim, who used pygame to lazy up the position calculations but then proceeded to turn it in to a pretty little animation.
I suspect part two of this puzzle would be difficult if you don’t scan your
input file quickly before starting. Given that we’re only seeing right
angles, we can just twiddle our waypoint with a rotation matrix. I’ll admit
I was about to break out the trigonometry here, but luckily I did quick
grep of the L and R entries. So, we’re left with:
if (action == 'L' and value == 90) or (
action == 'R' and value == 270
):
wpt_x, wpt_y = -wpt_y, wpt_x
elif value == 180:
wpt_x, wpt_y = -wpt_x, -wpt_y
elif (action == 'L' and value == 270) or (
action == 'R' and value == 90
):
wpt_x, wpt_y = wpt_y, -wpt_x
Tip
Like earlier puzzles it perhaps make sense to use a pre-written generic point class here, or reach for complex numbers to store the x and y coordinates.
Day 13¶
This was a strange one. If you’ve been playing along at home for the past few years, you’ll immediately say “oh, Chinese remainder theorem again”. That is my tip here, at least skim your previous solutions towards the end of November.
We’re almost upon the second week here, and the competition is getting
considerably more difficult. However, you can significantly lighten your own
load. Lean on pre-written libraries like numpy and networkx,
brush up on itertools and use sensible names for variables.
“Sensible names for variables?” I hear you say, but yeah. The simple ability
to ag or grep previous competition’s answers is a literal super
power. And, doing so is far easier if you’re not staring at reams of
i/x/n usage.
Day 14¶
My admission for today is that I quickly resorted to type ping-pong here, it is just too easy:
value_s = '{:036b}'.format(value)
value = int(''.join(value_s), 2)
I think my only insight in this puzzle was that you should work in reverse, doing so allows you to skip performing a bunch of writes. It is clear that only the final write to an address will matter, so keep a seen state and ignore duplicate memory addresses.
Note
My plan is to get back to this once I’ve completed the final puzzles. I need a break from this as much I wanted a break from working on the puzzles themselves, and the two week point seems like as good a time as any for a break.
Tips¶
I’m mostly repeating my tips from last year, the year before, and the year before that.
Don’t use this as an excuse to learn a new language. The puzzles aren’t really complicated enough to learn a new language beyond basic grammar. You may as well use it as an excuse to explore new features in a language you already know, or as an excuse to explore the standard library of your chosen language some more.
Read the problems deeply. The artificial nature of the puzzles often elides important information, or at least can often feel that way. These are puzzles so you should expect some vexation, and skimming for speed will make this worse!
If you’re going for the leaderboard you need to be really fast, so: Use fast languages, be all over your chosen weapon’s standard library, and use your editor’s snippets well. Every. Second. Counts.
And finally, keep your old solutions around either in files or in your REPL’s history as you’ll probably end up revisiting them, if not this year then maybe in the next.
Hopes for 2021?¶
Repeating number one from every year so far: That the options to pay for it are better next year. Each year I have to find a friend to make a donation in my place as the payment options are weak. It would be nice to not have to do so, and limiting payments to PayPal and Coinbase must be putting others off a donation entirely.
Number two? That it returns. I know I’ve moaned a couple of times in this document, but that is the joy of puzzles. If they’re not annoying you then they’re not challenging enough.
Authenticate this page by pasting this signature into Keybase.
Have a suggestion or see a typo? Edit this page