Estimated reading time: 9 minutes
Introduction to RCS¶
Warning
I’ve resurrected this text from my old UKFSN site because a couple of people asked me to, but I wouldn’t recommend using RCS to anyone at this point. It is mainly to help people who need to understand RCS because they have no choice, for example Gentoo users who are stuck with dispatch-conf (or so my mails tell me).
Abstract¶
This introduction is aimed at people with no experience of a VCS at all, but who do have a need for an easy to use and non-intrusive way to backup, store and annotate configuration files or 5000 file C source trees. This text is by no means an in-depth RCS usage manual, it is a short and fast way to get working with RCS.
RCS is great for small projects or managing the wealth of configuration files
in /etc. It provides a way to reduce the need for file backups(without
losing any backup quality or quantity), to annotate changes made to a file, to
allow other people to work on a file and an easy method to package patch/diff
files for distribution.
If you want more in-depth information about using RCS, or when you find you need more functionality from RCS, there is a HOW-TO at The Linux Documentation Project (direct link) and fantastic documentation is provided with the RCS package.
Diving in¶
RCS is that simple to use that I will jump straight in to an example.
$ mkdir RCS
The RCS directory holds the RCS control files, they contain all the data RCS needs to work.
$ cat >myscript.sh <<EOF
#! /bin/sh
# $Id$
echo "Hello World!"
exit 0
EOF
$ ci myscript.sh
RCS/myscript.sh,v <-- myscript.sh
enter description, terminated with single '.' or end of file:
NOTE: This is NOT the log message!
>> /bin/sh "Hello World!" example
>> .
initial revision: 1.1
done
The command ci (check in) is where the magic of RCS takes place.
We have decided we want to make a snapshot of our file, myscript.sh,
and use ci to add the file to revision control.
$ ls
RCS
The file we checked in appears to have disappeared, obviously it hasn’t but the
default behaviour of RCS is to remove the file we check in. You can choose
to keep a working copy with ci -u or ci -l (covered below).
$ ls ./RCS/
myscript.sh,v
In the RCS directory a file now exists with the same name as our script plus
a ,v. This is the file RCS uses to store all of its data in.
$ co myscript.sh
RCS/myscript.sh,v --> myscript.sh
revision 1.1
done
$ ls -l ./
drwxr-xr-x 2 james james 1024 Nov 4 11:29 RCS
-r--r--r-- 1 james james 95 Nov 4 11:29 myscript.sh
The command co (check out) pulls a current version(by default) from the RCS repository and places it in the current directory. Default behaviour is to check out a read-only version of the file.
$ co -l myscript.sh
./RCS/myscript.sh,v --> ./myscript.sh
revision 1.1 (locked)
done
The -l option to co (and also ci ) is
used to lock the file. This file now becomes a working file, which is
writable, and it also means other people can’t edit it until you have released
it or checked it in again.
Blindly using the -l option to ci/co is
not advisable, you should get in to the habit now of only locking files you are
working on. RCS uses locking to block other users from checking in changes
and will cause much grief if you use RCS on multi-user projects. It is much
better to use -u (or unlocked) when you ci in new
files/changes this way you will have access to a read-only version of the file
and it will allow other users to edit it.
$ cat myscript.sh
#! /bin/sh
# $Id: myscript.sh,v 1.1 2002/11/04 11:29:48 james Exp james $
echo "Hello World!"
exit 0
If you remember from the original file it contained $Id$ on a commented
line, this $Id$ is a keyword used by RCS that is substituted with
information about the current file. In this example the tag $Id$ is
expanded to read the filename, the revision number, the date and time of the
check in, the person who checked in the file, the state of the file and the
owner of the lock(if any).
There are many keywords available, including:
$Author$The name of the person who did the check in
$Header$The same as
$Id$but including the path for the file$Log$A full changelog for file from the ci annotations
Although using $Log$ seems like a good idea it does mean the size of the
file is increased a huge amount. All the changelog data is available with the
rlog command at any time and without filling the source file.
$ sed -ie 's/World/${USER}/' myscript.sh
$ cat myscript.sh
#! /bin/sh
# $Id: myscript.sh,v 1.1 2002/11/04 11:29:48 james Exp james $
echo "Hello ${USER}!"
exit 0
$ sh ./myscript.sh
Hello james!
So we have decided to make some changes to the file, and then tested it works.
$ rcsdiff myscript.sh
===================================================================
RCS file: RCS/myscript.sh,v
retrieving revision 1.1
diff -r1.1 myscript.sh
3c3
< echo "Hello World!"
---
> echo "Hello ${USER}!"
TEST$ rcsdiff -u myscript.sh
===================================================================
RCS file: RCS/myscript.sh,v
retrieving revision 1.1
diff -u -r1.1 myscript.sh
--- myscript.sh 2002/11/04 11:57:51 1.1
+++ myscript.sh 2002/11/05 03:52:14
@@ -1,4 +1,4 @@
#! /bin/sh
# $Id: myscript,v 1.1 2002/11/04 11:29:48 james Exp james $
-echo "Hello World!"
+echo "Hello ${USER}!"
exit 0
The command rcsdiff supplies an easy way to check changes in a file.
Using rcsdiff filename will output a generic context-free diff(and a small
RCS header to stderr ), or you can pass normal diff options to
rcsdiff. In the second rcsdiff command the
diff option -u is given to tell rcsdiff it
should output a unified context diff.
$ ci -u ./myscript.sh
./RCS/myscript.sh,v <-- ./myscript.sh
new revision: 1.2; previous revision: 1.1
enter log message, terminated with single '.' or end of file:
>> Changed World to ${USER} to give a more personal feeling
>> .
done
So now we have seen the changes made to the file, and are happy with them, we check in our new revision. RCS asks for a log entry, this will make our changelog output later. You can cancel the check in using the normal C-c (control C) method.
$ cat myscript.sh
#! /bin/sh
# $Id: myscript,v 1.2 2002/11/04 11:34:21 james Exp james $
echo "Hello ${USER}!"
exit 0
You can see above that when RCS checked in the new revision it also updated
the $Id$ tag.
$ rlog ./myscript.sh
RCS file: ./RCS/myscript.sh,v
Working file: ./myscript.sh
head: 1.2
branch:
locks: strict
access list:
symbolic names:
keyword substitution: kv
total revisions: 2; selected revisions: 2
description:
----------------------------
revision 1.2
date: 2002/11/05 04:01:13; author: james; state: Exp; lines: +2 -2
Changed World to ${USER} to give a more personal feeling
----------------------------
revision 1.1
date: 2002/11/04 11:57:51; author: james; state: Exp;
Initial revision
=============================================================================
The command rlog provides quick access to revision history for
files, it accepts multiple files per command line(using normal shell
wild-carding) and provides all the information RCS has on a file. Should you
ever need to only know the changes that were made to the current revision you
can use the -r option as in rlog -r filename. You can
also check changes between revisions of files using the command like rlog
-r1.1,1.2 filename.
The -r option of RCS is one of its most powerful, it is available
in all the commands and shares the same semantics throughout. If -r is used with ci it forces a bump, for example ci -r1.7
filename will force RCS to check in filename as revision 1.7. Used with
co you can pull any revision of the file from RCS history. Used
with rcsdiff you can create a diff between any revision under RCS,
for example rcsdiff -r1.1,1.8 -u filename will output a unified context
diff of the changes from revision
1.1 to 1.8.
RCS really is that simple to use, it does have many more options that are not covered here(see the man pages) but the power of RCS is how simple it is to use. It takes almost no time to setup, and probably less time then you currently spend on arranging backups. The command syntax is simple, and stable across the separate commands. It provides an immensely powerful way to control configuration files, source code, even revisions of binary files and of course silly little shell Hello World examples.
Recap¶
To recap on RCS usage
Make the
RCSdirectory.Insert RCS tags, such as
$Id$, in to your original files to help you keep track.Edit your files.
Use ci to commit your revisions to the RCS history and annotate changes made. You can also use rcsdiff to see what changes you have made, maybe to help you build your changelog information.
Advanced¶
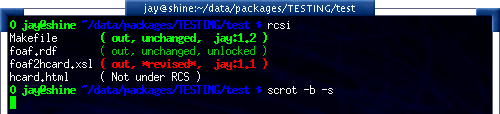
There are many tools available that can help you to manage your RCS files, including the RCS status monitor rcsi and blame RCS file annotator.
rcsi will display information about the files within a directory.
The screenshot to the right shows rcsi in use on a sample partially
RCS controlled directory. All the information it contains should be fairly
self explanatory, and even if it isn’t the package comes with a comprehensive
man page and README.
1.2 (root 21-Aug-05): eval find . -xdev -depth ${exceptions} -type d -empty -exec rmdir '{}' \\';'
1.2 (root 21-Aug-05): eend 0
1.2 (root 21-Aug-05): else
1.1 (root 16-Jul-05): ebegin "Cleaning /tmp directory"
1.4 (root 21-Jan-06): {
1.2 (root 21-Aug-05): rm -f /tmp/.X*-lock /tmp/esrv* /tmp/kio* /tmp/jpsock.* /tmp/.fam*
1.2 (root 21-Aug-05): rm -rf /tmp/.esd* /tmp/orbit-* /tmp/ssh-* /tmp/ksocket-* /tmp/.*-unix
1.4 (root 21-Jan-06): # Make sure our X11 stuff have the correct permissions
1.4 (root 21-Jan-06): mkdir -p /tmp/.{ICE,X11}-unix
The above excerpt is a sample of the output from blame being run against
a config file which is maintained using RCS by Gentoo’s
dispatch-conf tool. It allows you to simply see which revision
introduced a change to a specific line. You can also choose to annotate
specific RCS revisions using the --revision
option, or specific dates with --date option. blame
has also has a very comprehensive manual page included with it which you should
read if you want to enjoy its full power.
There are many other tools available which use RCS as a backend, and as long as you can access the RCS data files blame can help to understand what is happening with them too.
If you know of any interesting RCS uses please drop me a mail, and I hope this short text has been helpful to you.
Footnotes
RCS options:
- -r¶
Specify the revision to work with. Common across all of RCS’s tools.
blame options:
- --date¶
Annotate the revision that closest to, but not after, the given date.
- --revision¶
Annotate the revision numerically closest to, but not exceeding, the given revision.
ci options:
- -r¶
Perform checkin, and store with provided revision identifier.
- -u¶
Don’t lock the file on checkin.
co options:
- -l¶
Lock the file for editing on checkout.
rlog options:
- -r¶
Specify revisions to perform log against, can be a comma separated list of ranges.
Authenticate this page by pasting this signature into Keybase.
Have a suggestion or see a typo? Edit this page